 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMULTISEISMO: A Multimodal Seismic Dataset and Model for Cross-Modal Seismic Understanding
May 25, 2026The application of generalist multimodal models (GMMs) to specialized scientific domains remains limited due to the scarcity of comprehensive domain-specific datasets that integrate multiple data modalities beyond text and images. In seismology, understanding earthquake phenomena requires the synthesis of timeseries waveform data, geographical imagery, and contextual metadata, a multimodal integration absent in existing seismic datasets. We present MultiSeismo, a large scale structured multimodal seismic dataset, comprising over 16K seismic events spanning 13 years (2010 to 2023) across diverse geographical regions. Each event data integrates waveform recordings from global station networks, intensity maps, population exposure visualizations, and a comprehensive textual description within a standardized JSON format. We additionally develop MISCE, a multimodal instruction set on top of raw data to enable supervised training and evaluation of GMMs on seismic reasoning tasks ranging from basic information retrieval to complex cross modal analysis. We leverage MISCE to finetune an existing multimodal model (Unified IO 2) enhanced with a specialized timeseries encoder, which yields SeisModal, the first domain specific multimodal model for comprehensive seismic analysis. Evaluation of state of the art multimodal models on MultiSeismo reveals significant challenges, particularly with time-series data processing for general purpose models, while demonstrating SeisModal's superior performance on seismic multimodal reasoning tasks. These results prove that MultiSeismo provides a rigorous benchmark for future multimodal research in seismology and validate the success of our domain specific architectural adaptations.
Back to the Barn with LLAMAs: Evolving Pretrained LLM Backbones in Finetuning Vision Language Models
Apr 13, 2026Vision-Language Models (VLMs) have rapidly advanced by leveraging powerful pre-trained Large Language Models (LLMs) as core reasoning backbones. As new and more capable LLMs emerge with improved reasoning, instruction-following, and generalization, there is a pressing need to efficiently update existing VLMs to incorporate these advancements. However, the integration of new LLMs into VLMs, particularly how the evolving LLMs contribute to multimodal reasoning, alignment, and task-specific performance remains underexplored. Addressing this gap is important for VLM development, given the rapid evolution of pretrained LLM backbones. This study presents a controlled and systematic investigation of how changes in the pretrained LLM backbone affect downstream VLM task performance. By having the vision encoder, training data, and post-training algorithm remain same across LLAMA-1, LLAMA-2, and LLAMA-3 based VLMs, we find that newer LLM backbones do not always lead to better VLMs, but the performance depends on the downstream VLM task. For example, in visual question and answering tasks, newer LLM backbones tend to solve different questions rather than just more questions, and our analysis shows this is driven by differences in how the models process information, including better calibrated confidence and more stable internal representations. We also find that some VLM capabilities appear only in the newest LLM generation, while tasks that depend mainly on visual understanding see little benefit from a newer LLM backbone.
Surprisingly Fragile: Assessing and Addressing Prompt Instability in Multimodal Foundation Models
Aug 26, 2024



Multimodal foundation models (MFMs) such as OFASys show the potential to unlock analysis of complex data such as images, videos, and audio data via text prompts alone. However, their performance may suffer in the face of text input that differs even slightly from their training distribution, which is surprising considering the use of modality-specific data to "ground" the text input. This study demonstrates that prompt instability is a major concern for MFMs, leading to a consistent drop in performance across all modalities, but that instability can be mitigated with additional training with augmented data. We evaluate several methods for grounded prompt perturbation, where we generate perturbations and filter based on similarity to text and/or modality data. After re-training the models on the augmented data, we find improved accuracy and more stable performance on the perturbed test data regardless of perturbation condition, suggesting that the data augmentation strategy helps the models handle domain shifts more effectively. In error analysis, we find consistent patterns of performance improvement across domains, suggesting that retraining on prompt perturbations tends to help general reasoning capabilities in MFMs.
Generalist Multimodal AI: A Review of Architectures, Challenges and Opportunities
Jun 08, 2024



Multimodal models are expected to be a critical component to future advances in artificial intelligence. This field is starting to grow rapidly with a surge of new design elements motivated by the success of foundation models in natural language processing (NLP) and vision. It is widely hoped that further extending the foundation models to multiple modalities (e.g., text, image, video, sensor, time series, graph, etc.) will ultimately lead to generalist multimodal models, i.e. one model across different data modalities and tasks. However, there is little research that systematically analyzes recent multimodal models (particularly the ones that work beyond text and vision) with respect to the underling architecture proposed. Therefore, this work provides a fresh perspective on generalist multimodal models (GMMs) via a novel architecture and training configuration specific taxonomy. This includes factors such as Unifiability, Modularity, and Adaptability that are pertinent and essential to the wide adoption and application of GMMs. The review further highlights key challenges and prospects for the field and guide the researchers into the new advancements.
Whose wife is it anyway? Assessing bias against same-gender relationships in machine translation
Jan 10, 2024



Machine translation often suffers from biased data and algorithms that can lead to unacceptable errors in system output. While bias in gender norms has been investigated, less is known about whether MT systems encode bias about social relationships, e.g. sentences such as "the lawyer kissed her wife." We investigate the degree of bias against same-gender relationships in MT systems, using generated template sentences drawn from several noun-gender languages (e.g. Spanish). We find that three popular MT services consistently fail to accurately translate sentences concerning relationships between nouns of the same gender. The error rate varies considerably based on the context, e.g. same-gender sentences referencing high female-representation occupations are translated with lower accuracy. We provide this work as a case study in the evaluation of intrinsic bias in NLP systems, with respect to social relationships.
SCITUNE: Aligning Large Language Models with Scientific Multimodal Instructions
Jul 03, 2023



Instruction finetuning is a popular paradigm to align large language models (LLM) with human intent. Despite its popularity, this idea is less explored in improving the LLMs to align existing foundation models with scientific disciplines, concepts and goals. In this work, we present SciTune as a tuning framework to improve the ability of LLMs to follow scientific multimodal instructions. To test our methodology, we use a human-generated scientific instruction tuning dataset and train a large multimodal model LLaMA-SciTune that connects a vision encoder and LLM for science-focused visual and language understanding. In comparison to the models that are finetuned with machine generated data only, LLaMA-SciTune surpasses human performance on average and in many sub-categories on the ScienceQA benchmark.
Democratizing Machine Learning for Interdisciplinary Scholars: Report on Organizing the NLP+CSS Online Tutorial Series
Nov 29, 2022



Many scientific fields -- including biology, health, education, and the social sciences -- use machine learning (ML) to help them analyze data at an unprecedented scale. However, ML researchers who develop advanced methods rarely provide detailed tutorials showing how to apply these methods. Existing tutorials are often costly to participants, presume extensive programming knowledge, and are not tailored to specific application fields. In an attempt to democratize ML methods, we organized a year-long, free, online tutorial series targeted at teaching advanced natural language processing (NLP) methods to computational social science (CSS) scholars. Two organizers worked with fifteen subject matter experts to develop one-hour presentations with hands-on Python code for a range of ML methods and use cases, from data pre-processing to analyzing temporal variation of language change. Although live participation was more limited than expected, a comparison of pre- and post-tutorial surveys showed an increase in participants' perceived knowledge of almost one point on a 7-point Likert scale. Furthermore, participants asked thoughtful questions during tutorials and engaged readily with tutorial content afterwards, as demonstrated by 10K~total views of posted tutorial recordings. In this report, we summarize our organizational efforts and distill five principles for democratizing ML+X tutorials. We hope future organizers improve upon these principles and continue to lower barriers to developing ML skills for researchers of all fields.
How Well Do You Know Your Audience? Reader-aware Question Generation
Oct 16, 2021
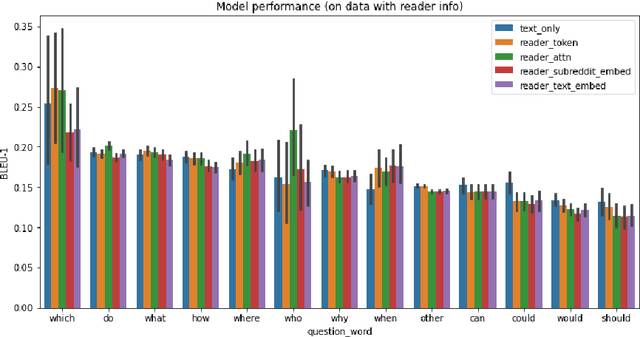

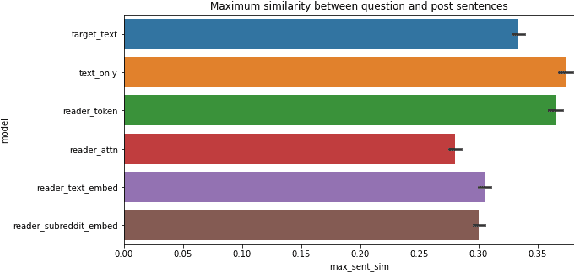
When writing, a person may need to anticipate questions from their readers, but different types of readers may ask very different types of questions. If someone is writing for advice about a problem, what question will a domain expert ask, and is this different from how a novice might react? In this paper, we address the task of reader-aware question generation. We collect a new data set of questions and posts from social media, augmented with background information about the post readers. Based on predictive analysis and descriptive differences, we find that different readers, such as experts and novices, consistently ask different types of questions. We next develop several text generation models that incorporate different types of reader background, including discrete and continuous reader representations based on the readers' prior behavior. We demonstrate that reader-aware models can perform on par or slightly better than the text-only model in some cases, particularly in cases where a post attracts very different questions from readers of different groups. Our work has the potential to help writers anticipate the information needs of different readers.
Room to Grow: Understanding Personal Characteristics Behind Self Improvement Using Social Media
May 17, 2021


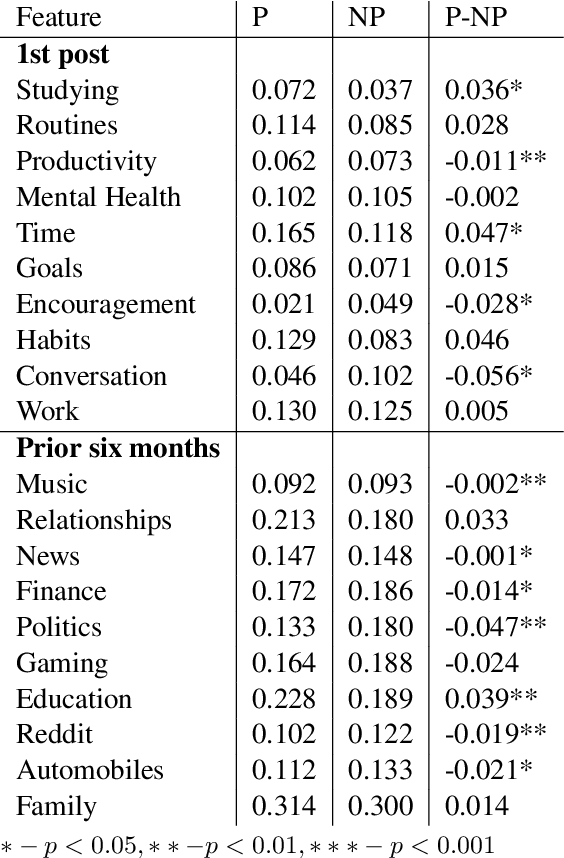
Many people aim for change, but not everyone succeeds. While there are a number of social psychology theories that propose motivation-related characteristics of those who persist with change, few computational studies have explored the motivational stage of personal change. In this paper, we investigate a new dataset consisting of the writings of people who manifest intention to change, some of whom persist while others do not. Using a variety of linguistic analysis techniques, we first examine the writing patterns that distinguish the two groups of people. Persistent people tend to reference more topics related to long-term self-improvement and use a more complicated writing style. Drawing on these consistent differences, we build a classifier that can reliably identify the people more likely to persist, based on their language. Our experiments provide new insights into the motivation-related behavior of people who persist with their intention to change.
Fill-in-the-blank as a Challenging Video Understanding Evaluation Framework
Apr 09, 2021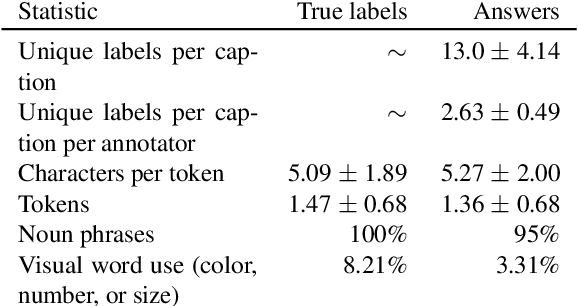
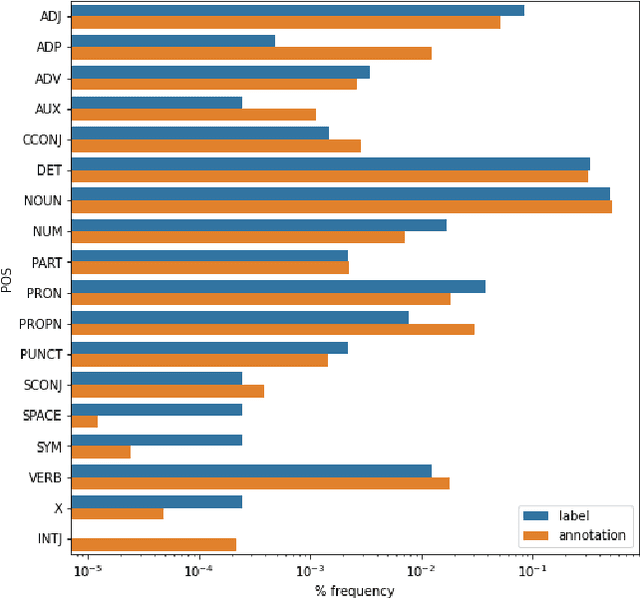
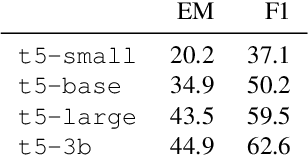
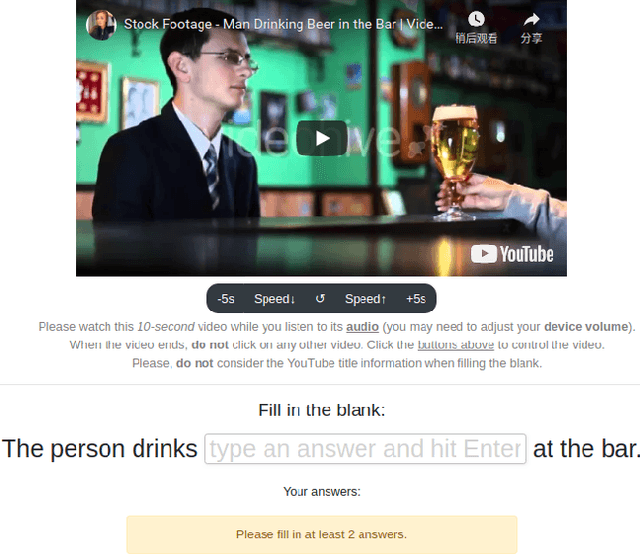
Work to date on language-informed video understanding has primarily addressed two tasks: (1) video question answering using multiple-choice questions, where models perform relatively well because they exploit the fact that candidate answers are readily available; and (2) video captioning, which relies on an open-ended evaluation framework that is often inaccurate because system answers may be perceived as incorrect if they differ in form from the ground truth. In this paper, we propose fill-in-the-blanks as a video understanding evaluation framework that addresses these previous evaluation drawbacks, and more closely reflects real-life settings where no multiple choices are given. The task tests a system understanding of a video by requiring the model to predict a masked noun phrase in the caption of the video, given the video and the surrounding text. We introduce a novel dataset consisting of 28,000 videos and fill-in-the-blank tests. We show that both a multimodal model and a strong language model have a large gap with human performance, thus suggesting that the task is more challenging than current video understanding benchmarks.